汎用性の高い多変量データ解析を用い
実社会のさまざまな情報・現象の解明を目指す

情報科学研究科 コンピュータサイエンス専攻
数理計算科学講座 情報解析学研究室・教授
博士(工学)今井 英幸
プロフィール
1987年、北海道大学大学院工学研究科情報工学専攻修士課程同修了。同年、北海道根室高等学校教諭。1989年北海道大学工学部助手、翌年、同大学院工学研究科助手に配置換え。2000年、同大学院工学研究科助教授、同大学院情報科学研究科助教授を経て、2009年、同大学院情報科学研究科教授に昇任。2005年、Seventh International Conference on Computing Anticipatory Systems (CASYS’05)におけるBest Paper Award受賞。
さまざまな情報を集約・可視化する
多変量データ解析手法の開発
先生の研究室ではどのようなことを研究しているのですか。
今井 主にデータの理論的解析からソフトウェア開発まで広範囲にわたる研究を行っています。データは基本的に①ある特定の目的を持って集められたもの(定型的なデータ)と、②日常的な活動の中で蓄積されたもの(非定型的なデータ)の2種類があります。
定型的データの典型は、学生の学力試験の結果、世論調査、臨床試験に使われるような患者と検査結果のデータなどがあります。非定型的データの例はメール、TwitterなどのSNS、POS、インターネットショッピングの購入履歴などが上げられます。近年の「ビッグデータ」と呼ばれているものも非定型的データの一種です。
私たちの研究室では長年定型的なデータの解析手法を研究しています。例えば、センター試験の結果であれば、数十万人の受験生×5科目といった大きなデータが得られますが、それを元に、平均を取る、最高点・最低点を求めるなど必要な情報を得るための処理を行い、直感的に把握しやすいようなものに集約・可視化していきます。
こうした解析に用いられるのが「多変量データ解析」です。多変量解析とは、複数の結果変数からなる多変量データを統計的に扱う手法で、技術そのものは古くからあったのですが、コンピュータの計算能力が低い時代には処理に時間と労力がかかっていました。近年はパソコンの発達のおかげで身近に使えるようになり、活用範囲が広がっています。
デジタル画像データを統計的に処理し
欠損・劣化のある画像を鮮明化
最近の研究成果にはどのようなものがありますか。

今井 多変量解析が対象としているものは幅広く、世の中にあるものはだいたい扱えると言ってもいいほどです。例えば、デジタル画像のデータも多変量解析の対象となります。デジタル画像は、画素数256×256=65,536で、画素の濃度は256階調に量子化されています。このようなデータは多変量データと考えることができ、画像の拡大や修復、色の補正、ピンボケの修正などが多変量解析の手法を使って行うことができます(解説1)。
コンピュータは修復前のオリジナル画像を知っているわけではありませんから、数学的に推測して復元します。多変量解析を使って復元する方法にもいくつか種類があり、その中から一番いいものを統計手法で選び出していきます。
画像認識は、統計の中の大きな研究テーマのひとつでもあります。画像認識には、画像の一部が欠損していたり、逆に余計な雑物が混じっていたりしても間違いなく強靱(ロバスト)な認識ができるよう設計することが求められています。私たちの研究では、画像の中の異物が全体に影響しないような手法を組み立て、より鮮明かつ正確に復元する技術を追求しています。
先生の研究の独自性・優位性はどのような点ですか。
今井 前述の多変量データ解析の手法には「これ以上精度が上がらない」という限界があります。画像認識や復元にもこれ以上良くならないという限度があるのです。私たちの研究室では、それをきちんと把握し、切り分けて考えるようにしています。何にでも使えるオールマイティな方法はなく、データの精度や仮定の条件が整っていなければ正しい近似値が出せない場合もあります。そういう意味では、「ここまでは多変量データ解析でうまくいくが、これ以上は無理」という限界を理論的に明らかにすることが必要だと考えています。
他分野の研究者へもネットワークを広げ
新しい研究テーマに積極的に取り組む
現在、どのようなことに興味をもっていますか。

今井 今興味を持っているのは、近似値を使わずに精密な値を求める手法の研究です。じつは、統計的なデータは何らかの仮定が設定されているため、10の100乗や200乗といった量の数を足し算するのが難しく、積分を使って近似値を求める方が使われてきました。近似値の精度を上げる研究も長年続けられています。
しかし、最近は計算に必要な数値だけを抽出して数え上げることができるようになってきました。マルコフチェイン(連鎖)モンテカルロ法(解説2)と呼ばれるもので、理論的には古いものですが、計算機の性能向上によりさまざまな場面で利用できるようになりました。必要な値をすべて数えることができれば、近似値より精密な結果が得られます。情報科学の分野ではこの手法の研究が活発に行われていますが、統計やデータ解析にはあまり使われていないので、興味を持って取り組んでいるところです。サンプル数が少ないデータの解析に有効なので、大量の測定データが入手しにくい分野で役立つのではないかと考えています。
現在、どのようなことに興味をもっていますか。
今井 冒頭で、データには2種類(定型的・非定型的)あるとお話ししましたが、今後は、非定型的データの活用手法にも取り組んでいきたいと考えています。メールやTwitter、Webのページビューなどは、目的があって収集されているものではなく、勝手にどんどん蓄積されていくデータです。従来の統計手法では、「これが知りたい」という前提がなければうまく活用できないので、日々蓄積されていく膨大なデータから何を掴むのか、まずはそこを探究することが必要だと思います。
また、ネット上を飛び交うデータの解析は、量的なものだけでなく「中身」が重要になってきます。ある時期急激にSNSの投稿が増大したら、そこに何が書かれているのかが問題になってくるでしょう。現在は、出現する単語や人名の頻度は勘定できても、中身にまでは踏み込んでいません。自然言語解析などは私の研究の範疇でないので、それらの分野の研究者と共同研究の機会があればぜひ取り組んでみたいテーマです。
また、ネット上に流れる情報だけでなく、屋内外に設置したセンサや衛星画像などを統合することで、今まで見ることができなかった人間の行動や社会現象などが分かるかもしれません。プライバシーやセキュリティをいかに守るか、ビジネスとしていかに成立させるかなどの課題はありますが、今後研究する価値のある分野だと期待しています。
解説
解説1:画像処理とその応用
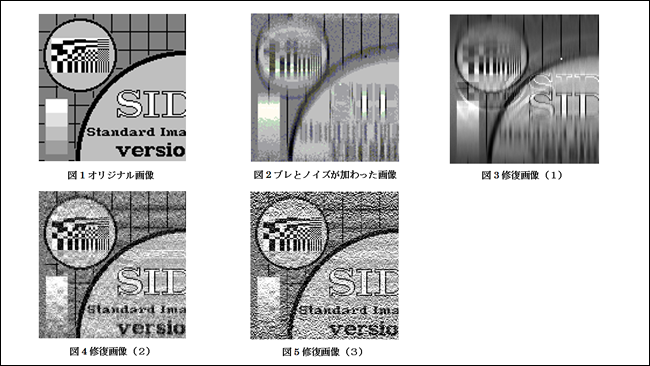
オリジナル画像(図1)に上下方向のブレとノイズが加わった画像(図2)を3種類の方法で修復した(図3、図4、図5)。オリジナル画像はわからないので図1~図3の中でどれが最もよい修復画像であるかを統計的な手法で比較すると図4(修復画像(2))が最適な修復画像として選択される。選択には情報量規準という方法が使われている。
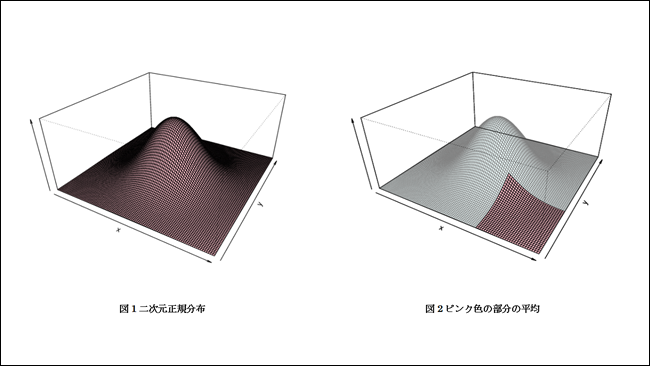
解説2:マルコフチェイン(連鎖)モンテカルロ法
釣鐘を伏せたような形の図1は二次元正規分布とよばれる。全体の体積は1で平均(全体が釣り合うところ)は釣鐘の一番高いところである。その一部分だけを切り取った立体(図2)の平均を求めたい。図2のような二次元の立体であればさまざまな方法で求めることができるが、三次元、四次元と次元が高くなるにつれて通常の計算で求めることは難しくなる。このような場合でもマルコフチェインモンテカルロ法を使うと平均の近似値を求めることができる。 この例のように、コンピュータの計算能力を利用することで通常の計算では求めることが難しい値をもとめることが可能になる。