
類似性と差異を高速かつピンポイントに検出
「気づきにくいが重要」な情報を発見するマイニング手法の開発

情報科学研究科 情報理工学専攻
知識ソフトウェア科学講座 知識ベース研究室・教授
博士(理学)原口 誠
プロフィール
1979年鹿児島大学理学部数学教室助手。1981年九州大学理学部付属基礎情報学研究施設助手。1987年東京工業大学大学院総合理工学研究科助教授。1995年北海道大学大学工学部教授。2004年北海道大学大学院情報科学研究科教授。
主な研究テーマは高次推論、知識表現、データマイニング
データ・情報・知識の背景にある文脈を通じて新たな知識を取り出す
知識ベース研究室の研究テーマはどのようなものですか。
原口 まず、知識ベースという言葉の意味からご説明します。コンピュータの世界で扱われる情報や知識には大きく3つあります。①データベースなどに蓄積されているローレベル(観測データ等の加工されていない生の状態)の「データ」、②Web上に存在するテキストや画像などの主観的で意味を持った「情報」、③ある現象から次の現象を予測・類推したり、物や状況の構造・属性などを表す「知識」の3つです。従来のデータマイニングは、これらのデータ・情報・知識から重要な情報を得ることを目的とし、主として頻度情報にもとづく統計処理と組合せ論的アルゴリズムの手法を用いて研究が行われてきました。
私たちの研究室が扱う知識ベースは、もう少し広い意味で捉えています。なぜなら情報や知識というものには、地域、文化、コミュニティ、個人の感情といった背景に無限のバリエーションがあり、使う人や使う目的によって意味や価値が異なってくるからです。例えば、「りんご」という言葉一つ取っても、赤いりんごをイメージする人と青いりんごをイメージする人では言葉のとらえ方が違ってきます。このように言葉や文章の背景にあるもの(コンテクスト:文脈)までも正しく捉えなければ、より有益なデータマイニングにはつながらないと考えているのです。
私たちの研究では、こうしたテキストベースのデータ・情報・知識をもとに、時間や地域性、文化などのコンテクストを通して知識を取り出すプログラムの開発を主なテーマとしています。
類似性と差異を検出するためのプログラムの開発
具体的にはどのような研究が行われているのですか。

原口 前述のようにコンテクストには無限のバリエーションがあり、それらの多様性をすべてカバーしたルールセットを獲得することは困難です。しかし、コンテクストが違えばそこに何らかの現象が現れるのではないかと考えられます。そこで、コンテクストが違っても変わらないもの(類似性)と変わるもの(差異)に着目し、それらを検出するためのプログラムの研究開発に取り組んでいます。
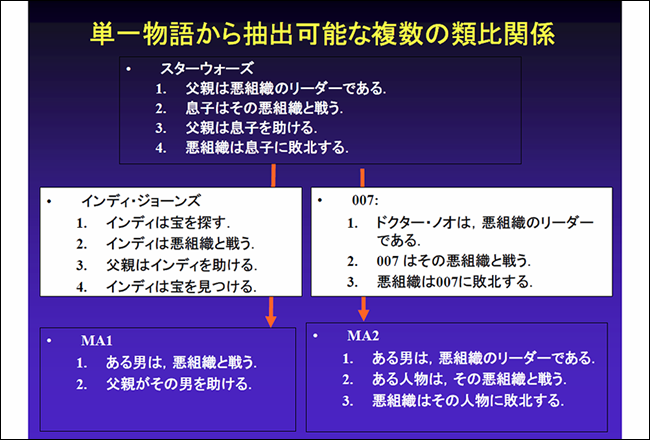
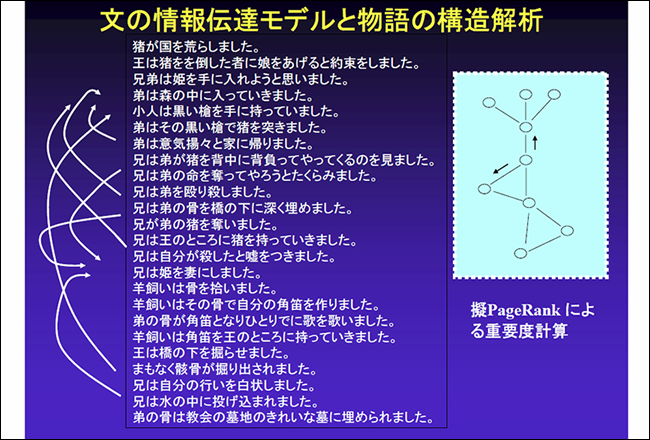
類似性の検出では「物語データベース」と呼んでいるプログラムを開発しました。オンライン文書を話の筋や展開構造からデータベース化するもので、異なる二つの物語を比較し、構造的な類似性を検出することに挑みました。
計算時間や深い意味レベルでの検出の観点からはまだまだ課題を残していますが、物語り要約の技法も取り込んだ形で今後も継続していきます(解説1)。
差異の検出には2つの手法を考えています。まず1つは「グラフの差異の検出(解説2)」です。例えば、新聞記事に登場するある言葉と、それに関連づけられるいくつかの言葉をクラスタリングする場合、評価値の高いクラスタのみを抽出するためのアルゴリズムを開発しています。一般的なやり方では、抽出されるクラスタが膨大な数になってしまう、あるいは、少数だが大きすぎるクラスタしか抽出できないので、いかにして高速に検出対象となる比較的小規模のクラスタを抽出する点が最大の特徴です。
もう一つは「相関マイニング」というもので、文書内の言葉の相関量の変化を見つけて差異を検出するプログラムです。アメリカのデータベースを使って言葉(カテゴリー属性名)の相関を調べたところ、ある年代では「若い農夫」と「家のローンを組む」という言葉の相関は非常に薄かった。それが、年代が進むと相関関係が微増してくる。その原因は何かを調べてみたら、微増した年代の少し前にサブプライムローン政策が打ち出されていたことが分かりました。
また、日本の新聞記事のデータベース使った実験では、大きな災害があった直後に「外国人医師」と「国際空港」の相関の量の増加が検出され、海外からの医師が支援のために来日していたことがわかりました(解説3)。このように、相関量の変化から思いがけない言葉の組合せが検出されれば、新しい知識の発見につながるのではないかと予想しています。しかし、言葉の組合せの可能性は膨大であり、コンテクストをどう扱うかは根本的な問題として残されており、まだまだ発展途上の研究です。
筋肉の動きを測定し、動作の「質」の解明に迫る
これらの研究は今後どのような分野へ展開するのですか。

原口 次のステップとして考えているのは「スキルの学習」です。運動機能をデータとして収集して動きのパターンを検出するプログラムで、スポーツや楽器の演奏などの上手下手の違いを解明したり、上手くなるためのスキルの習得を目指したものです。筋電センサという筋肉の活動電位を測定・記録する装置で筋肉の動きの時系列データを取り、上手い人に共通するもの(類似性)と下手な人との違い(差異)を検出します。ただデータを表示するだけではなく、それを人の動作という抽象度の高い記述に変換する手法の開発がポイントになります。
体の動きというのは言語化しにくいものであり、個人差や育った環境などによっても上手下手の具合が異なってきます。テキストデータにおけるコンテクストよりさらに曖昧で微妙な部分が多く、そう簡単に「上手くなる方法」が見つかるわけではありません。しかし、こうした研究を通じて本人さえ気づいていないようなことが発見できれば嬉しいですね。
情報技術の発展によりWebの世界には膨大なデータが蓄積されています。それらを効率よく活用し、私たちにとって有益な知識を高速にピンポイントで発見する。比較的に安価な観測機器がネットワークに接続されつつある現状を考えれば、動作データも今後急速に蓄積され、データの単なる再現・視覚化のみならず、データ活用法そのものに多くの可能性が広がってくると思います。
解説
解説1:物語データベース
オンライン文書を話の筋や展開構造からデータベース化する試み。テキスト間の構造類似性の検出や結束性と文脈性に基づく文の評価などを行う。
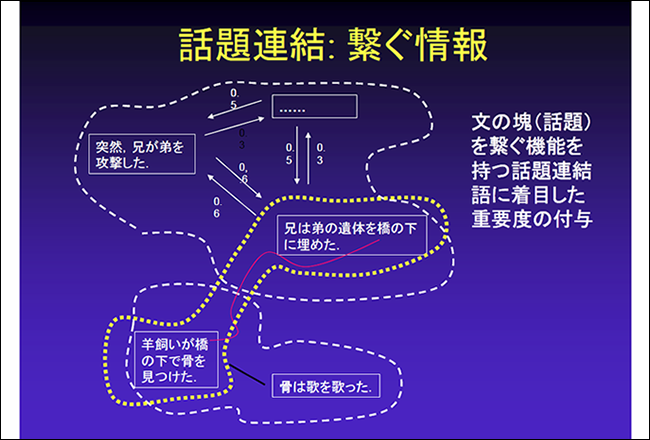
解説2:グラフの差異の検出
グラフ構造における差異の検出をターゲットとし、異なる地域、イベント発生の前後等、異なるグラフを比較し差異を表す頂点集合を検出する方法。
資料1
資料2
解説3:相関マイニング
複数の単語の相関量の差を求めることで関係性の変化を検出する手法。この方法では、データマイニングにおいて最も基本的なトランザクションデータベースに対する手法を与えている。
まず、いわゆる属性の集まり(アイテム集合)で、一方のデータベースで相関が低く、もう一つのデータベースで相関がある程度高くなるものを求める。
相関差異が大きな場合は、目立った変化として比較的抽出しやすい話であり、例えば、相関を変数集合に対するカイ2乗統計量で計量した場合は、一方のデータベースで無相関(独立)だが、時間や場所の変化に伴い強い相関を示すものを抽出することになる。
本研究ではそうではなく、相関の兆しをみつけることが目標であり、そのためには、より膨大な属性集合をチェックする必要性があり、その問題を克服するための技法を組み込んでいる。
(資料:A. Li, Aixiang, M.Haraguchi and Y.Okubo:Contrasting Correlations by an Efficient Double-Clique Condition,Transactions on Machine Learning and Data Mining, 5(1), pp. 3 - 22, ibai Publishing, 2012.)