Finally I have checked the agreement between a fast version of my morality checker and human subjects.
Another surprise
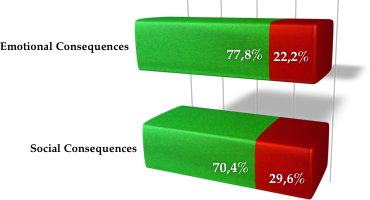
I have started to write a program that analyses massive amounts of sentences to discover who is doing what to whom, for how long, with what intensity, etc. and what kind of consequences follow such an act. The road is long and far from end but in the meanwhile, as you may remember, I was asked to make a live demo of such a "majority decides for a robot" algorithm for Japanese national TV. The only way was to make a simple matcher for simple input and it worked well enough to satisfy the TV people. However, as I never treaded this version seriously (no semantics involved, only scratching the surface of meaning) I haven't done any check of the results brought by the demo. But we had a little technical meeting at our uni and I thought it may be a good opportunity to show what such a simple program could do. So I asked 9 students of mine to evaluate how moral or immoral are the acts I prepared before as an input set. It appeared that categorizing only the emotional consequences brings almost 80% of correct answers and social consequences about 70%. The difference, I think, comes from the type of text used - people are more emotional in blogs, but if (for example) newspapers corpus was used - surely social consequences would bring more correct judgements. Now I am coming back to semantics hoping that the 80% level is a starting point.