From connecting to finding - establishment of the theory of knowledge creation

Hiroki Arimura, Doctor of Science,
Professor of the Graduate School of Information Science and Technology, Hokkaido University,
Division of Computer Science's Research Group of Knowledge Software Science
Adoption of a global COE program to elicit knowledge from a sea of information
In June 2007, Next Generation Information Technology Bases to Support Knowledge Creation was adopted as a global COE program. Dr. Arimura, you serve as the project leader. What were the circumstances in which the project was applied for and adopted?
Dr. Arimura: The Global COE program is a successor of the 21st Century COE Program (Ex. 1) started by our laboratory in FY2002. In the 21st Century COE program, considerable results have been achieved in research and development of information processing communication technologies, which freely interconnect data and systems on the Internet. The new Global COE Program aims to establish theories and technologies for creating new knowledge from the state where everything is interconnected. It is a new step from connecting to finding.
I hear that the fields of information, electricity and electronics were highly competitive, with very few projects adopted. What were the points that led to the high estimation of your project?
Dr. Arimura: First, we highlighted the concept of knowledge creation to discover and coordinate pieces of knowledge as a new discipline. Today, we can easily obtain large amounts of information thanks to the popularization of the Internet. Also with the dramatic progress of observation and measurement technologies, we can now obtain data on various events and phenomena that could not be accessed in the past. Although we are now facing an unprecedented ocean of information, new knowledge cannot be created only by increasing the amount of information because discovering specific or remarkable patterns from chaotic, large amounts of data, and reading their hidden meanings can be too complex and enormous to handle. To find the value concealed in this ocean of data, it is necessary to develop new information technologies, academic bases, and human resources. I think one of Japan's most innovative ventures was to establish a university education and research program for that purpose and develop a concrete plan for it.
The fact that young researchers of our graduate school played a central role in compiling the outline of the program was also highly valued. More than half of the researchers in this program, including myself, are in their thirties or forties. Such people thought about what would be necessary for future university education and what they should do beyond the boundaries of their specialties. The strong backing of the Dean and senior professors strongly support us.
Crossover between the information world and the real world / fostering human resources with a high degree of professionalism and a broad outlook
What are the specific contents of the Global COE Program?
Dr. Arimura: One of its characteristics is that it is a joint research project of three fields - information, biotechnology and nanotechnology. Being the program leader, I am a sub-leader in information retrieval and data mining. The sub-leaders are Professor Yoshikazu Miyanaga, Hidemi Watanabe and Kazuhisa Sueoka. Professor Miyanaga specializes in media networking, Professor Watanabe in life sciences with a focus on gene analysis, and Professor Sueoka in nanoelectronics. A interdisciplinary team from the fields of information hardware/software, life sciences and nanotechnology is aiming to develop new research areas. Knowledge and technology in the information world are significant only when they are useful in the real world. Meanwhile, theoretical and technical development has been achieved by utilization of information technology in biotechnology, nanotechnology and other fields in the real world. Although these fields look very different at first glance, they are actually closely related each other. Then, if researchers in different areas can find out unexpected connection among them and exchange scientific views and ideas each other, more rapid and meaningful knowledge creation may be achieved at a deeper level. I strongly feel that this is possible.
Another characteristics of the program is its double-major human resource development. Hokkaido University has a tradition that placed importance on practical science since its foundation. Graduate schools require students to take four credits in a minor field besides their specialty in the Master's course and eight credits in the second minor in the Doctoral course. It is a very unique curriculum among Japanese national universities, in which students can acquire education and experience in other fields while engaging in profound study of their specialties. This is an essential qualification for research and development of technologies that are useful in the real world, and researchers and engineers who have graduated from Hokudai are always highly valued by companies and research institutes. Such tradition is handed down to young students currently studying in the graduate school to train them to be leaders in new academic fields. The emphasis on graduate school education is also a significant feature of this COE program.
In fact, our graduate school has fostered development of an integrated research system of three fields - electricity, electronics and informatics - since its foundation in 2004 through the previous 21st COE program, in which hardware and software researchers cooperate with each other beyond their individual realms of expertise. This means that the system already has the ability to create knowledge, but we wanted more. The application of the program has also given the main members an opportunity to engage in thorough discussions. I think it has been a very important process not only in terms of application, but also for members'understanding of each other, the characteristics of this graduate school and its future direction.

Research on semi-structured data mining to find the relationships among pieces of knowledge and data
In establishing the theory of knowledge creation, the research on semi-structured mining that you are conducting, Dr. Arimura, is playing an important role.

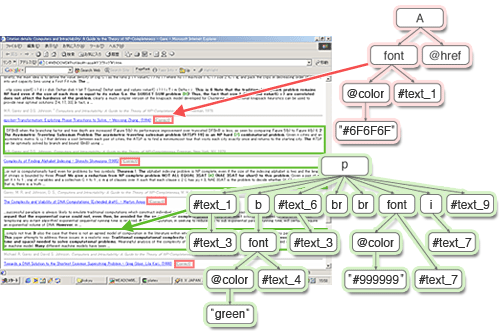
Dr. Arimura: While it is said that the Internet contains data on an exabyte scale (i.e. to the 18th power of 10), most of this is simply an enormous accumulation of individual pieces of knowledge. It is very difficult for one researcher to understand all the pieces of this mixture of knowledge, relate each other the various fields involved and conduct cross-sectional research. My research theme is therefore the semi-automatic extraction of useful patterns and rules to help human's acquisition of knowledge. Through the research adopted for the 2001-2005 Grant-in-Aid for Scientific Research on the Priority Area of Information Sciences and the study entitled "Efficient Pattern Discovery from Massive Semi-Structured Data for Knowledge Infrastructure Formation on the Web" (adopted for the 2005-2007 Grant-in-Aid for Specially Promoted Research), we are conducting research and development for a technology to find specific rules and patterns from web pages, XML data and other semi-structured information sources (Ex. 2). Through these research efforts, a tree-mining algorithm known as FREQT has been developed, with which characteristic partial structures in a collection of tree-structured data can be discovered as small tree patterns (Ex. 3/Fig. 1).
Semi-structure mining is considered useful in biotechnology and nanotechnology research. In genome analysis, for example, each combination of some elements, e.g., gene, amino acid, or protein, had to be verified to extract, classify and analyze the functions and manifestation patterns of individual genomes. Using semi-structure mining, it becomes possible to compare all the genomes simultaneously and extract their common rules and patterns. Stable performance of the FREQT algorithm on live data has already been confirmed, and it is expected to be fully suitable for use on a business basis as well as in biotechnology, nanotechnology and other research fields. We intend to disclose these mining engines through the Internet and other media to help the discovery and coordination of knowledge.
Explanation
Explanation 1: 21st Century COE Program
This was launched in FY2002 as a project (Grant-in-Aid for Forming Research Locations, etc.) of the Ministry of Education, Culture, Sports, Science and Technology according to the guidelines for reforms at universities. Its purpose is to form world-class research and education bases in Japanese universities, to promote the improvement of research standards and the development of creative human resources to lead the world, and to facilitate the international competitiveness of universities. In FY2002, Meme-Media Technology Approach to the R&D of Next-Generation Information Technologies was adopted as a subject at the Graduate School of Engineering. With Professor Yuzuru Tanaka as the project leader, we have integrated the technologies of knowledge media, quantum nano-structures and intelligent communications for research and development of a quantum-integrated circuit with a new architecture, IQ chip technology with a communication function (achieved by using the circuit), and knowledge media technology (achieved using these chips).
Explanation 2: Semi-structured data
These data do not have a predetermined format, although they themselves have structure in the same way as XML data with a tree structure. In the case of tree mining, characteristic partial structures are found as small tree patterns from the semi-structured data existing in a tree formation.
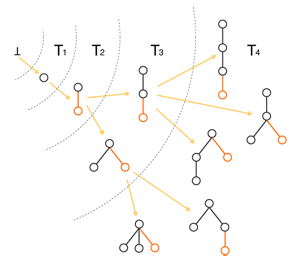
Explanation 3: FREQT high-speed discovery algorithm with performance guarantee
FREQT uses the world's first polynomial time algorithm, known as rightmost expansion. If it is set to add new peaks (red parts) only on the right side when adding tree elements, tree structures for all patterns can be generated automatically (Fig. 2). Besides tree data, a variety of combinations can also be listed efficiently. There has even been a case where a tree structure was constructed from a Japanese document through a natural-language processing technique, then had FREQT applied to it to perform text mining. It is expected that FREQT will be applied in a variety of fields as a high-speed, robust and highly general-purpose algorithm.