検索結果の関係性や時間変化を予測する高度な検索エンジン
ヒューマンコンピュテーションと機械学習で効果的に実現

情報科学研究科 複合情報学専攻
複雑系工学講座 表現系工学研究室・准教授
博士(情報学)小山 聡
プロフィール
1994年、京都大学工学部数理工学科卒業、1996年京都大学大学院工学研究科数理工学専攻修士課程修了、2002年京都大学大学院情報学研究科社会情報学専攻博士後期課程修了、博士(情報学)。1996〜98年日本電信電話株式会社、2001年より日本学術振興会特別研究員、京都大学大学院情報学研究科助手、スタンフォード大学計算機科学科visiting assistant professorなどを経て、2009年より現職。主な研究分野は機械学習、データマイニング、情報検索など。2005年度人工知能学会論文賞、2009年度日本データベース学会上林奨励賞受賞。
人工知能とソフトウェア工学を両輪とした研究領域
先生の研究室ではどのような研究を行っているのでしょうか。
小山 ふたつの大きな柱があり、ひとつは人工知能に関する研究。もうひとつはソフトウェア工学です。私たちの研究室では『知的にソフトウェアをつくりたい 知的なソフトウェアをつくりたい』というテーマを掲げ、「より高性能」なソフトウェアを「より簡単・確実」に設計する技術と理論を研究しています。
人工知能(AI)というのは人間のような高度な知能をもった機械で、そのほとんどはソフトウェアで制御されています。それらのソフトウェアを一から十まで人の手で作るのではなく、設計や構築にも機械の助けを得て、効率良く、賢く、なるべく労力をかけずに品質の良いものを作ろうというのが私たちの目指しているところです。人工知能とソフトウェア工学の2つを両輪として研究・教育を行っている研究室は全国的にあまり多くはなく、「異分野の融合による新研究領域の創出」や「幅広く総合的な高等教育」を標榜している北海道大学情報科学研究科の特徴のひとつでもあると言えるでしょう。
その中でも、私は人工知能の機械学習を専門に研究しています。機械学習自体は比較的基礎的な技術ですが、学習というのは知能における非常に重要な機能なので、高度な機械学習を実現することは人工知能の開発にも大きく貢献することになります。
同姓同名を見分けるオブジェクトレベル検索
具体的な成果はありますか。

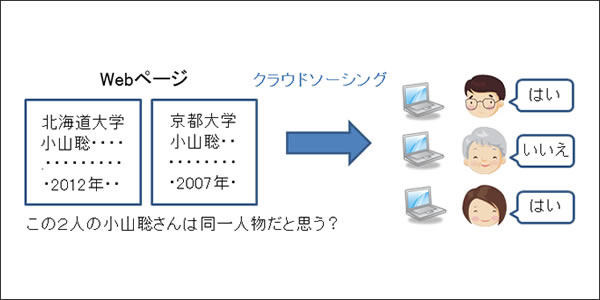
小山 現在進めているのは、情報検索やデータマイニングに関する研究です。インターネットを利用する人のほとんどがYahoo!やGoogleなどの検索エンジンを使っていると思いますが、これらのWeb検索は、キーワードを入れるとそれにヒットするページが一覧で表示されます。例えば、私(小山聡)の名前を入れると、もちろん私のページも出てきますが、同姓同名の人のページも出てくる。また、私に関する情報も北海道大学のサイトや研究室のページ、SNSなど複数のページに分かれていて、本当に必要な情報にたどり着くのは結構大変です。
こうした課題に応えるのがオブジェクトレベルの検索です。私というオブジェクト(実体)に関する情報を自動的に抽出し、まとめて表示する方法です。重要なのは、小山聡に関する情報が載っているページがいくつかあるとき、それが同じ人物について書かれているかどうかを判定する必要があるということ。私たちの研究では、オブジェクトを特定し、他のオブジェクトと区別する機能の実現に機械学習を取り入れています。
通常の機械学習では、例えばある画像に対し、それが花の画像なのかそうではないのかを分類します。しかし、私たちが取り組んでいるのは、2つのデータの関係を予測するというものです。ひとつのページについて「これは小山聡に関するものか、そうではないか」を判定するのではなく、「このページの小山聡と、別のページの小山聡は同一か」を判定するのです。一つひとつのデータを分類するより複雑で難しい問題になるので、精度良く予測できるようなアルゴリズムを開発しています。(解説1)
もうひとつは、圧力センサーによる認証(解説2)です。椅子に圧力センサーを取り付け、座る人のクセを読み取ることで認証を行います。座り方には意外と個性が出るもので、被験者がリラックスした状態であれば98%の精度で認証できることがわかりました。座り方の特徴を捉えることで個人認証する技術はおそらく世界初だと思います。
さらに、オブジェクトの時間変化を識別する手法にも取り組んでいます。例えば、私が10年前に書いた論文と現在書いている論文の内容は違いますが、双方の関係性や変化の傾向を予測して、同じ人物が書いたものかどうかを判定するのです。
労力を軽減し学習効果を高めるクラウドソーシングの活用
機械学習はどのように行うのですか。

小山 機械学習は、最初に「こういう場合はこう判断しなさい」といういくつかの例題を示して、そこから学習していくのが一般的です。訓練用のデータを与えるのは人間の手で行わなくてはならないのです。じつは、それが今までの最大の難点でした。訓練データを作って与える人間が研究者自身やその協力者、学生のアルバイトやボランティアなどに限られ、労力やコストが負担になっていたのです。
今、その部分を効率化し、しかも豊富な訓練データを入手する方法として「クラウドソーシング」が注目されています。インターネットを通じて不特定多数の人にデータ分類などの簡単なタスクを依頼するものです。アメリカではamazonなどが仲介者となってクラウドソーシングが普及しつつあり、日本でも同様のサービスが始まっています。報酬を支払ったり、ゲーム感覚で参加してもらうなど多様なスタイルがありますが、今までとは桁違いの量のデータが収集でき、研究者の労力を軽減するだけでなく機械学習を用いたソフトウェアの開発スピードと精度の向上も期待できます。(解説2)
これまでの人工知能研究では、人間の手を一切借りずに、すべて自動で行うことができる機械をつくることが最終目標のように考えられてきました。しかし、近年はコンピュータよりも人間が得意な問題では、人間の手を借りる方が早く、しかも効果が高いという認識も生まれています。人間と機械の得意な部分をうまく組み合わせることで、全体として精度の高いシステムを作る。人間と機械が補い合う「ヒューマンコンピュテーション」はこれからの主流になっていくと考えられ、私にとっても非常に興味深い分野です。
解説
解説1:ペアワイズ分類器の学習とアイデンティティの推定
Web時代には、正体や素性の分からない人物が「誰であるか」を特定するアイデンティティの推定が必要になる。その顕著な例が同姓同名の問題で、情報の利用者が情報発信者の信頼性を判定したり、サービス提供者が適切なサービスをするうえでもアイデンティティの推定は重要となる。本研究では、2つの例が同じクラスに属するか否かを判定するペアワイズ分類(pairwise classification)の学習など、アイデンティティの推定に必要な技術に関する研究を行っている。
小山 聡: アイデンティティを推定する, 人工知能学会誌, 24(4), pp.544-551, 2009.
小山 聡, クリストファー D. マニング: 異なる例からの素性の組合せを用いたペアワイズ分類器の学習, 人工知能学会論文誌, 20(2), pp.105-116, 2005.
解説2:クラウドソーシングを用いた大規模情報統合に関する研究
「名寄せ」など、異なる情報源からの情報の統合に関する問題に対応するため、インターネット上で不特定多数の人に仕事を依頼し、データの同一性の判定などを行ってもらう。依頼する側(リクエスター)は労力と時間の軽減ができ、参加する側(ワーカー)は報酬やプロジェクトへの参加意識の共有といったメリットが得られる。ただし、得られたデータの信憑性も考慮しなくてはならないので、ワーカーのスキルや作業結果の信頼性を評価する手法の開発も進められている。