
遺伝的アルゴリズムを用いた帰納的学習による言語処理
言葉を覚えて成長するコンピュータを目指して

情報科学研究科 メディアネットワーク専攻
情報メディア学講座 言語メディア学研究室・教授
博士(工学)荒木 健治
プロフィール
1982年、北海道大学工学部電子工学科卒業。1988年、同大学院工学研究科情報工学専攻 修士課程修了。1988年 同電子工学専攻 博士後期課程修了(工学博士)。1988年、北海学園大学工学部電子情報工学科 助手。1998年北海学園大学工学部電子情報工学科 教授。1998年、北海道大学大学院工学研究科 電子情報工学専攻 助教授。2002年、同大学院工学研究科電子情報工学専攻 教授。2004年、同大学院情報科学研究科メディアネットワーク専攻 教授。
<在外研究歴>
1992年9月から1993年9月米国スタンフォード大学 CSLI(言語情報研究所)客員研究員、 2000年7月から2000年8月米国スタンフォード大学 CSLI(言語情報研究所)客員研究員、 2009年9月から2009年12月米国スタンフォード大学 CSLI(言語情報研究所)客員研究員
電子情報通信学会、人工知能学会、日本認知科学会、情報処理学会、言語処理学会、Association for Computational Linguistics(ACL)、The Institute of Electrical and Electronics Engineering(IEEE)、The American Association for Artificial Intelligence(AAAI)所属
人間が言葉を覚えるメカニズムをコンピュータで実現
言語メディア学研究室ではどのような研究をおこなっているのですか。
荒木 人間が言語を獲得していくメカニズムを解明し、工学的に実現することを目標に研究を行っています。具体的には、言葉を覚えて成長するコンピュータの実現です。私には3人の子どもがいるのですが、最初の子が生まれた時、言葉を覚えていく過程がとても興味深く、これをコンピュータでつくってみたいと思ったのが始まりです。
アシモのように人間と言葉を交わすロボットやシステムはすでに存在しています。しかし、そのほとんどは人間があらかじめプログラムしたものであり、複雑な質問や想定外の要求に答えることはできず、相手を理解しているわけでもありません。本研究が目指しているのは、人間の赤ちゃんと同じように学習を通して自ら成長し、理解する能力を獲得するシステムです。私が研究を始めた1980年代は、人間の言語獲得に関する研究は発達心理学の領域とされ、コンピュータを使って工学的に実現するというアプローチは非常に珍しいものでした。
コンピュータが他者(主に人間)とコミュニケーションしながら言葉を学習し、大人と同じように話せるようになるには、人間が通常使う言葉(自然言語)の処理能力が必要です。本研究ではまず、自然言語処技術の研究に取り組みました。知識ゼロの状態から、対話を通じて単語や文法などのルールを学習し、やがて発話できるようになる。最終的には完全な言語理解ができ、会話だけでなく文書の検索や要約、高度な翻訳などができことを目指しています。
遺伝的アルゴリズムを用いた帰納的学習の開発
赤ちゃんと同じように言葉を覚えるコンピュータとはどのような仕組みなのでしょうか。

荒木 本研究では、コンピュータにあらかじめ正解をプログラムすることはせず、学習する仕組みだけを与えました。教師役である人間と雑談レベルの対話を繰り返し、その中からルールを獲得していきます。学習する手法には帰納的学習(解説1)を独自に開発し,利用しました。
学習による言語獲得は、①帰納的学習による形態素解析、②帰納的学習によるかな漢字変換、③遺伝的アルゴリズムを用いた帰納的学習による機械翻訳手法、④遺伝的アルゴリズムを用いた帰納的学習による音声対話処理手法の4段階で高度化させていきました。①と②は帰納的学習により8〜9割程度の精度が得られたのですが、③は帰納的学習だけでは不十分だったため、遺伝的アルゴリズム(GA)を導入しました。これを「GA-IL(Inductive Learning with Genetic Algorithms)」と呼んでいます。さらに④では雑談程度の対話例から学習していくシステムとして「GA-ILSD(Spoken Dialogue method using GA-IL)」(解説2)を開発しました。言語処理で遺伝的アルゴリズムを使ったのは世界初の試みです。
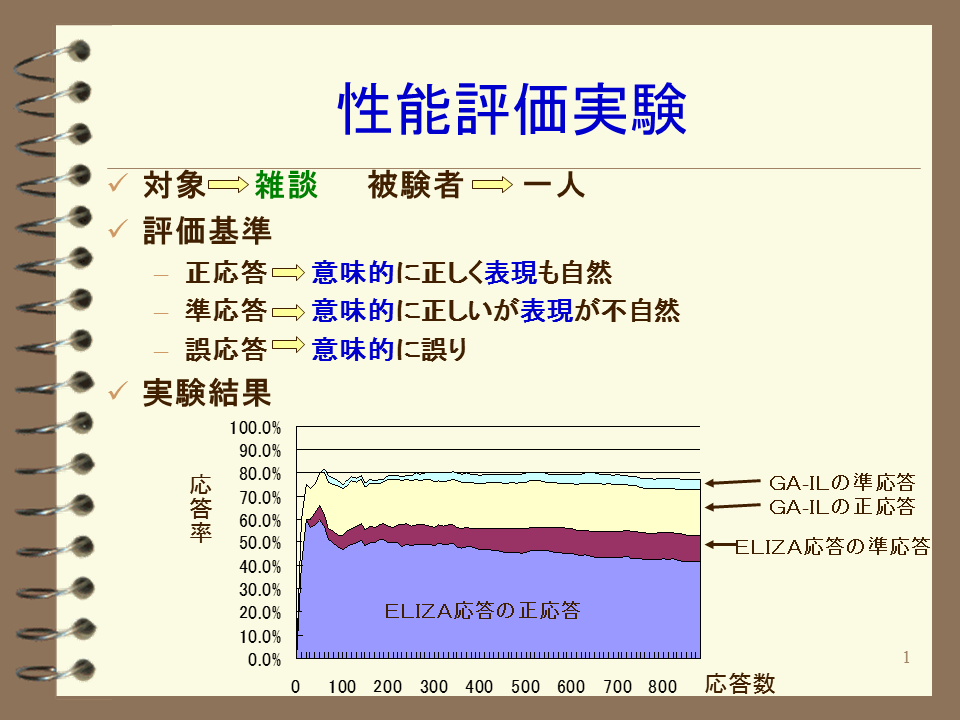
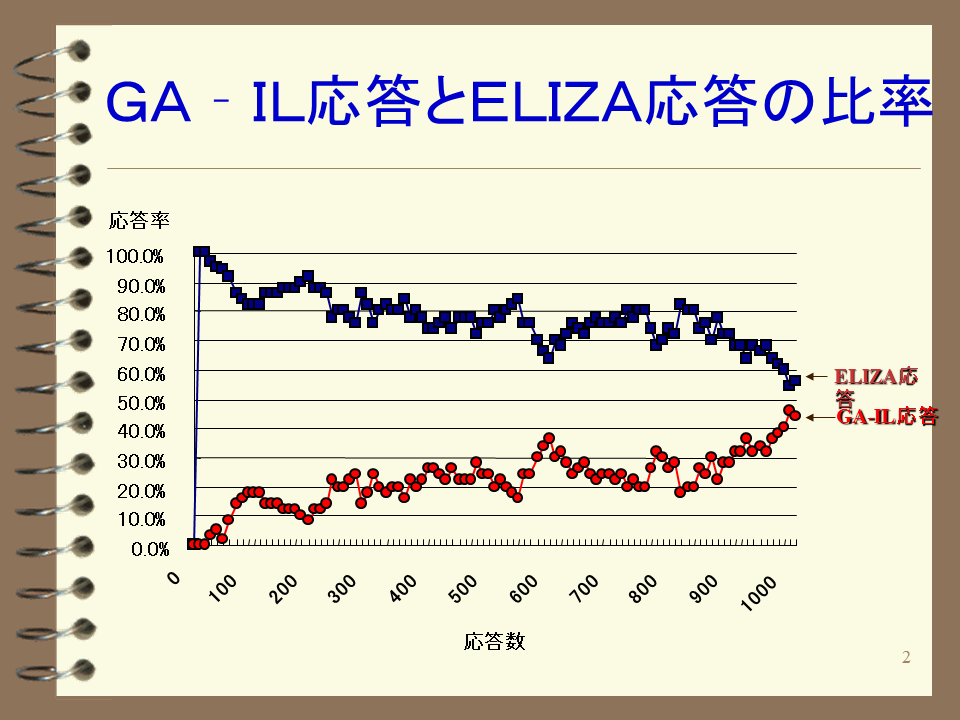
GA-ILSDでは、対話を継続させるためにELIZA(解説3)を組み込みました。ELIZAは、応答文の生成ルールが十分に存在しない時、単純な応答で対話を継続させながら対話例を収集していきます。学習が進むにつれ応答文生成ルールが増大し、GA-ILの応答が増えていきます(解説4)。性能評価実験(図1)では、GA-IL応答とELIZA応答の比率(図2)を見るとわかるように100応答あたりでGA-ILの発話が活発になり、1,000応答程度でELIZAとGA-ILの応答率がほぼ同じになることが実証されました。このことは、GA-ILの学習の有効性を示しています。
3歳児の壁を越える「常識」と「感情」の獲得
GA-ILSDはどの程度の言語獲得能力があるのですか。

荒木 現在、GA-ILSDは約8,000対話経験で雑談レベルの会話ができるぐらいに成長します。これは人間でいうと3歳児ぐらいの能力で、現段階ではこれが限界です。人間は4〜5歳になると論理的な思考ができるようになり、そこから本質的な人間へと成長していきます。3歳の壁を越えるには、論理的な思考が生まれる過程で何が起きているのかを解明しなくてはなりません。私たちは、そこに「常識」と「感情」があるのではないかと考えています。
まだ言葉を話せない赤ちゃんでも、物理法則に反した物の動きを見ると驚きます。また、泣いたり笑ったりすることで意志や感情を伝えようとします。赤ちゃんは、生まれながらにして「常識」や「感情認識」といったものを身につけていると考えられているのです。これは、学習によって得られたものではないので、コンピュータに教えてやる必要があります。本研究では、ネットや人間の教師から得た常識をデータベース化し、常識を使って言語獲得する研究にも取り組んでいます。同時に感情を認識する技術の研究も進めています。
さらに、その先にはコンピュータが「自我」を持つこともあり得ると考えています。自我の存在は人間にとっても未知の問題であり非常に哲学的なテーマですが、いずれ実現するのではないかと思います。アメリカの未来学者レイ・カーツワイルは、21世紀中に訪れる「技術的特異点(シンギュラリティ)」について言及し、今後30年ほどで人工知能が人間の知能を超えると予言しています。その先、人類がどのように進化していくかは見えません。人工知能が人類を敵と見なして滅ぼす可能性もあります。それがわずか30年後にやってくると予測されているのです。これからのロボット開発は、ロボットが必ず正しい方向へ行くように何らかの制約を付ける「ロボット倫理学」についてもきちんと考えなくてはならないでしょう。
私たちのつくるシステムが「自我」を獲得したとき、それが人間らしさを身につけた友となるのか、人類に襲いかかる敵となるのか。私たちは今、とても重要な分岐点に立っていると思います。
解説
解説1:帰納的学習
帰納的学習によるルールの獲得には(1)選択:共通部分を有し,差異部分を両辺に1つのみ持つルールのペアを選択。(2)生成:差異部分のみを抽出、または 差異部分の変数への置き換え。(3) 生成された新たなルールを加えて繰り返す。(4) 新たなルールが生成されない場合終了。以上4つのプロセスがある。


解説2:遺伝的アルゴリズムを用いた帰納的学習
遺伝的アルゴリズムを用いた帰納的学習は,変換規則を獲得する学習エンジンであり,対応関係を有する一対の組より,抽象度の異なるルールを多段階に獲得し,それらのルールを用いて変換を行う。(1)変換部:獲得した変換ルールより適用可能な変換ルールを選択し,適用する。この際に,適用可能な変換ルールを対象に交叉処理により新しい変換ルールを自動的に生成する。(2)校正部:変換結果を人手により正しい変換結果に校正する。(3)学習部:入力文と校正済みの変換結果の組より多段階に抽象度の異なる変換ルールを獲得する。この際に,交叉処理により新たな実例を自動生成する。 (4)フィードバック部:変換結果と校正済み変換結果を比較することにより,誤りを発見し,精度を適応度として変換ルールの淘汰処理を行う。以上4つのプロセスがある。
解説3:ELIZA
1966年にJ. Weizenbaumが開発した 精神科医のインタビュー代行システム。キーワード方式とアドホックな方法で うまく話題をそらして会話を継続しようとするが、 ユーザの満足度は低い。

解説4:GA-ILSDの処理過程
GA-ILSDはELIZAの頑健さ(対話の継続)とGA-ILのよる具体的な応答を組み合わせ、 ユーザの興味がある話題に追従しながら対話例を獲得する学習型音声対話システム。学習が進むにつれて応答文生成ルールが増大し、 ユーザの興味に即した具体的応答が増大する。