
膨大なデータの中から有用な知見を発見する機械学習
工学以外の分野への応用に貢献する技術開発に期待

情報科学研究科 情報理工学専攻
知識ソフトウェア科学講座
大規模知識処理研究室・准教授
博士(工学)瀧川 一学
プロフィール
1999年、北海道大学工学部卒。2004年、同大学院工学研究科博士後期課程修了(博士(工学))、北海道大学情報科学研究科博士研究員(COE)。2005年、京都大学化学研究所バイオインフォマティクスセンター助教。2007年、同薬学研究科医薬創成情報科学専攻助教。2010年、ボストン大学バイオインフォマティクスプログラム客員研究員。2012年、北海道大学創成研究機構特任助教(テニュアトラック)。2014年より同情報科学研究科准教授。
グラフ構造を持つデータを機械学習で解析
瀧川先生の研究テーマについてお聞かせください。
瀧川 主な研究テーマは機械学習です。機械学習は与えられたデータからコンピュータ自身が有用な規則やルール、知識表現、判断基準などを抽出してアルゴリズムを発展させる技術です。特に私が興味を持っているのは、機械学習を使って化学研究のデータを解析するというものです。前職が京都大学化学研究所のバイオインフォマティクスセンターで、遺伝情報や分子レベルの計測データを活用して生物学的な知見を発見する研究に携わっていました。生物学の専門家ではなかったのですが、ゲノムデータの解析などを通じて化学分野で機械学習を活用することに興味を持ち、本研究室でも引き続き研究を行っています。
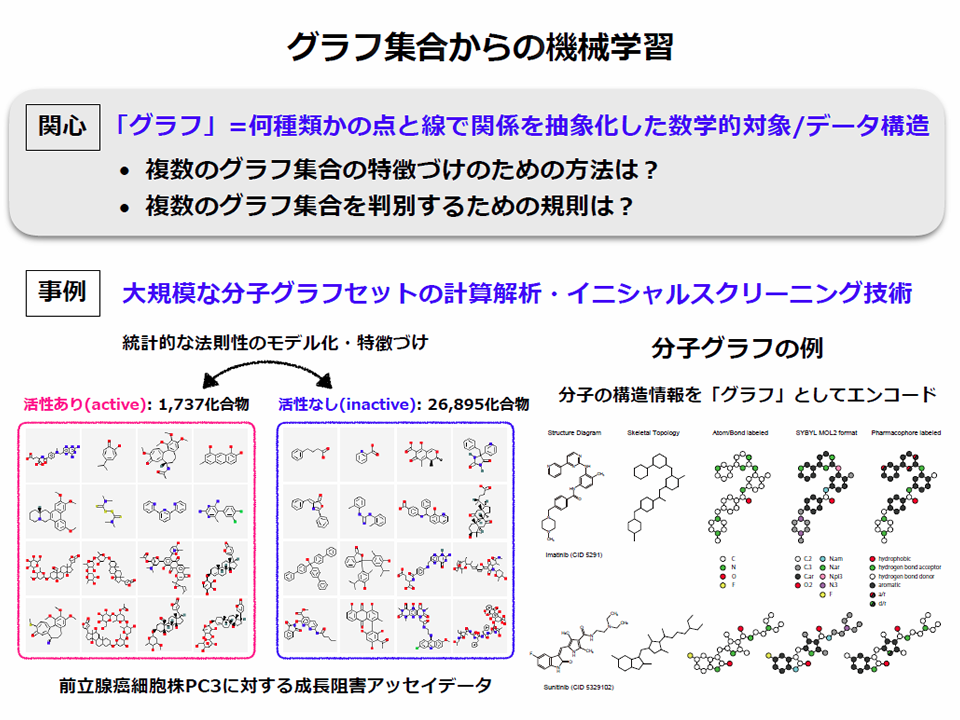
ポイントはグラフ構造を持ったネットワーク状の知識表現を伴うデータ解析(解説1)です。この場合のグラフとは何種類かの点と線の集合で表される数学的対象あるいはデータ構造の意味で、頂点と辺のラベルは離散的と仮定しています。化学や薬学の分野では、材料となる化合物の分子を分類・比較しながら新しい化合物を探りますが、分子構造のわずかな違いで薬の作用・副作用が異なります。そこで、一つひとつの分子構造(化学構造式)をグラフとして扱い機械学習で解析するのです。従来は、ベテラン技術者の経験と勘で探り当てることも可能でしたが、2005年にヒトゲノムが解明されるなど近年はデータ量が膨大になったため、コンピュータを使って効率よく高速に有用な知識を抽出する機械学習の技術が注目されています。
深層学習で電子物性を予測する技術の創出
現在どのような研究がおこなわれているのですか。

瀧川 科学技術振興機構のさきがけプロジェクトに採択された「大規模データに基づく電子物性予測のための深層学習技術の創出」があります。これは、物質・材料に関する大規模なデータの中から、望ましい性質を持つ新物質・材料の探索や、背景にある構造活性相関・物理法則の理解による設計支援に利活用することを目指したものです。
深層学習(解説2)とは、特徴となる表現(記述子や構造指数)を機械学習で自動獲得する手法です。画像検索などに実際に使われ、大量のデータの中から人の顔の特徴を自動で抽出し人物を特定することができます。さきがけのプロジェクト(解説3)では、物質の適切な特徴量を深層学習で自動獲得し、目的とする特徴の高精度な予測技術の確立を目指しています。
前述の分子構造の違いが薬効の違いとして表れるように、物質・材料の場合は電子の分布量(電子密度)によってその性質が決まります。そこで電子密度のシミュレーション技術と深層学習を結びつけることで、高速かつ高精度な解析技術を探求しています(図2)。この技術が確立すれば、対象や問題に依存性のない汎用技術として幅広く応用できると期待しています。
機械学習を高度化し工学と生命科学・化学・物理学をつなぐ
機械学習にはどのような可能性があるのでしょうか。

瀧川 私はもともと機械学習をテーマとする工学系の研究者ですが、京都大学でバイオインフォマティクスに関わることで生命科学や化学の分野の知識も得て、両方をつなぐポジションで研究できることがとても面白いと思っています。それぞれの専門家が共同研究の形でコラボレーションすることはありますが、お互いの文化の違いが高い壁になってしまうケースも少なくありません。
情報科学はデータから新たな知見を得るための道具であり、道具が高度化すれば今までにない新しいものが発見できます。近年はさまざまな分野で大量のデータが公開され、多様な活用の仕方が出てきています。分野によってデータの構造や条件、特徴などは異なりますが、分野に特化した解析技術を個別に用意するのではなく、できるだけ汎用的な技術を確立することが重要だと考えます。とはいえ、あまり汎用的すぎると使い勝手がよくないこともあるので、その中間的な機能を実現するには、工学と多分野の両方の知識に精通していることが求められます。工学的な立場からは、どのようにデータを利活用するかという方法を考えることと、その方法を使うとどのようなことができるのかを保証すること、その二つを意識していきたいと思います。
解説
解説1:グラフ集合からの機械学習
グラフ(graph)は離散・組合せを扱う数学や計算機科学の対象としても馴染み深いが、「graph」という専門用語が最初に使われたのは分子グラフの研究であり、多様な歴史とその汎用性の点で非常に面白い対象である。
(参考:「グラフ理論への道
1736-1936」(N.L.ヒッグス,他 著,一松信,秋山仁,他 翻訳)」)
瀧川一学,
多数のグラフからの統計的機械学習
(深化する機械学習:技術の進展とその応用特集号).システム/制御/情報,
2016;60(3):106-111.
瀧川一学,
データマイニングとしての多重標的相互作用解析.日本薬学会・構造活性相関部会
SAR NEWS, 2015;29:9-17.
瀧川一学・馬見塚 拓,
化学とグラフアルゴリズム
(ヘッドライン:化学と数学の接点).化学と教育,
2011;59(9):450-453.
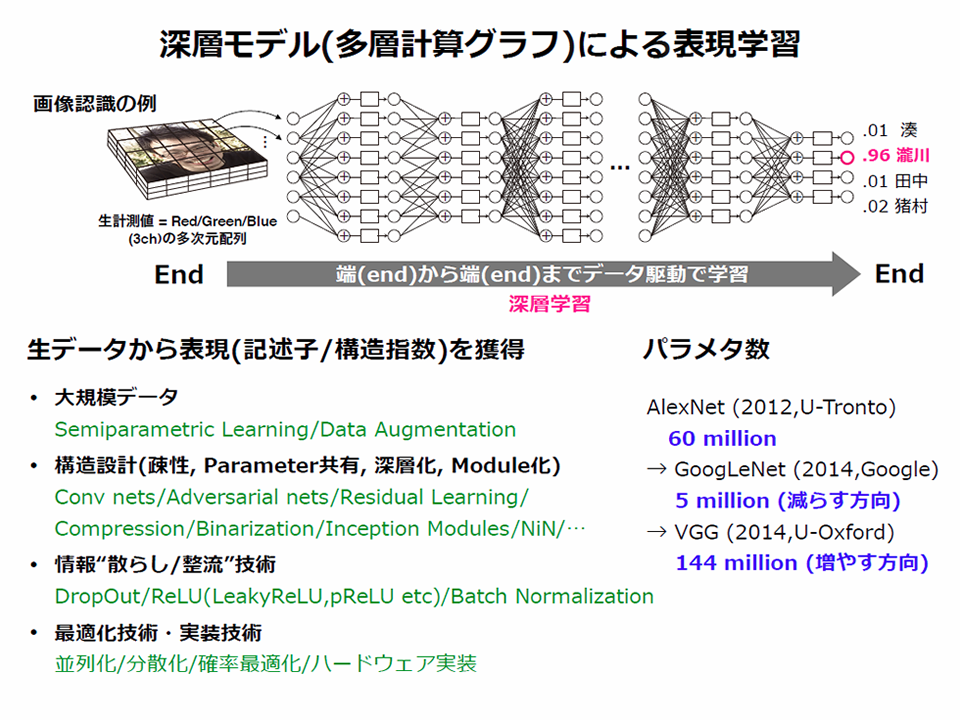
解説2:深層学習, 表現学習, 多階層計算グラフ
従来、無加工の生計測データをそのまま機械学習にかけても精度は出なかったため、画像認識や音声認識など各々の個別の問題ごとに人手で有効特徴量の設計や評価の研究が行われてきた。
近年、「深層学習」として、多階層計算グラフに基づき生データから有効特徴表現を獲得するための汎用的枠組みが確立し、多数の課題での成功例が報告されている。特に、データが多量に利用できるケースで有効であることが示唆されており、現在も研究が活発に行われている。伝統的な統計モデルはデータが多量にあっても少数のサンプルで推定した際と精度はほとんど変わらない。むしろ少ないデータから物を言うための理論としてこの点は要求されてきたとも言える。一方、深層学習では、基本的にデータが増えれば増えるほどモデルに取り込み精度向上が見込める。そのため、現代の多様な大量データを活かす技術として産業や科学でも注目され、特にインターネット企業の屋台骨を成す基幹技術として既に確立する他、多数の製品やサービスも溢れるようになった。
現在はまだ技術研究の過渡期であるが、さらに研究が進めば、個別の問題ごとに人手の有効特徴量の設計をすることなく、多量のデータと深層学習という単一の枠組みのチューニングで、できるだけ人手の恣意性を介することのない汎用のend-to-endな学習技術の確立が期待されている。
解説3:JSTさきがけ・マテリアルズインフォマティクス領域

理論・実験・計算科学とデータ科学が連携・融合した先進的マテリアルズインフォマティクスのための基盤技術の構築