
ディープラーニングから見えてくる知性の本質を探り
ロボットやAIなど幅広い分野への展開を目指す

情報科学研究科 情報理工学専攻
複合情報工学講座 自律系工学研究室・教授
博士(工学)山本 雅人
プロフィール
1991年北海道大学工学部情報工学科 卒業、1996年同大学院工学研究科システム情報工学専攻 博士後期課程 修了。1996年4月〜1997年7月日本学術振興会特別研究員(PD)。1997年8月より北海道大学大学院工学研究科助手、助教授(准教授)を経て2012年12月に情報科学研究科教授に就任。研究分野は人工生命/人工知能、ソフトコンピューティング、ゲーム情報学、観光情報学。
鳥の群れはどのように方向を決めるのか?
ディープラーニングで進化の過程に迫る
自律系工学研究室ではどのような研究を行っているのですか。
山本 「生命知能の理解と創造」をテーマに、ディープラーニング(深層学習)などからヒントを得た人工生命や人工知能の研究を行っています。「生命知能」とは脳の部分だけをターゲットにしているのではなく、身体性や関係性も含めた捉え方をしています。ロボットなどの機械には実体があり、実際に動くからこそ出てくる知能があるのではないかというアプローチです。
自律系の研究には大きく3つのジャンルがあり、①人工知能や深層学習などの問題を扱うIntelligence、②人と人、人と機械、あるいは群れといった複数の個体の相互作用や関係性を扱うInteraction、③認知科学や脳計測を含む⼈間の理解を扱うMindの3つです。それぞれの分野で多様な研究を進めていますが、今回はその中で3つのテーマを取り上げたいと思います。
まず一つは「群れ行動の創発」です。ハトやムクドリが大群となって飛んでいるところを見たことがある人も多いかと思います。鳥の大群は波のように動いたり一斉に向きを変えたりしますが、どうやって目的の方向に向かうのかというメカニズムはよくわかっていません。
私たちは、お掃除ロボットのように二輪走行するロボットを用いて、お互いの運動しか認知できない状況下で、ロボット同士がどのようにコミュニケーションを取り、どのように行動を決定するかをシミュレーションしました。(解説1)。
3体のロボットにはセンサが搭載され、自分以外のロボットまでの距離が分かるようになっています。与えられたタスクは①お互い一定の範囲内の距離を保つこと、②できるだけ遠くまで移動することの2つだけです。3体のロボットは同じニューラルネットワークによって制御され、タスクを達成するために遺伝アルゴリズムによって進化していきます(動画1)。2〜3時間の進化のあと、最初はお互いの位置を探るように⼩刻みに動くのですが、そのコミュニケーションの中からどれか⼀体が先頭になり⼀列になって移動するようになります。つまり、コミュニケーションを通じて役割が生まれます。どのロボットが先頭になるかはランダムで、確率的には3分の一ずつです。現在は、学習した3体のロボットを10〜20体の群れの中に入れたらどうなるかという実験も進めています。
ロボットが周囲の景色から自分の位置を推定
景観の特徴点を自ら抽出・比較する手法の開発

山本 ⼆つめのテーマは人間の理解に関した研究テーマである「⾃⼰位置推定」です。 ロボットを自律的に動かすには自分の位置を正確に知らなければなりません。あらかじめマップが与えられていたり、対象物との距離が測れるセンサなどがあれば比較的簡単ですが、例えば災害が起きて建物の形が変わっていたり、GPSが使えない屋内などではロボットが自分で推定しなくてはなりません。
本研究で取り組んでいるのは、人間が周囲の景色を見て自分の位置を知るように、カメラを搭載したロボットが周囲の景色を撮影し、そこから自分の位置を推定するディープラーニング手法です(解説2)。
マインクラフトというゲーム環境の中に単眼カメラを搭載したロボットを置き、撮影しながら自分がどこにいるかを推定します。ロボットには、あらかじめ見えてる角度と地点を結びつけた座標をいくつか教えておきますが、移動後の画像との相違点を抽出し、そこから自分の位置を推定する方法はディープラーニングで学んでいきます。従来は「この景色が見えたらここ」という知識も教えなければなりませんでしたが、ディープラーニングでは正解の位置をいくつか教えておけば、場所が変わってもそこに結びつく特徴を自分で見つけだすことができます。しかし、ロボットが景色の中の何を特徴として捉えているかは私たちにはわかりません。そこがAIの特性なのです。
マインクラフトの環境での検証を行いました。移動ロボットに正解の座標をいくつか与えたのち、⾃分で撮影した数枚の写真を⼿がかりに⾃⼰位置推定します。検証の結果、最初の⼀枚では性能が落ちるのですが、2枚⽬以降では誤差が徐々に下がって、精度が上がっているのがわかりました。
ゲームの局面から勝率を計算
不確定要素も考慮した戦略支援ツール

山本 三つめのテーマは「ゲームAIの開発」です。ゲームAIというと将棋やチェスなどが有名ですが、実はスポーツの世界でもゲームAIの技術が応用できます。その一つがカーリングです。最近人気のスポーツで「氷上のチェス」とも呼ばれています。なぜチェスなのかというと、ストーンを投げた後の配置(局面)から数手先を読みながらゲームを進めるからです。ただし、将棋やチェスは駒を置く場所(座標)が決まっていますが、カーリングは狙い通りの位置にストーンが行かないこともしばしばあります。そのため、先読みする場合の座標が確定していない(不確定要素が多い)のが大きな課題です。
この課題を解決するため、私たちはデジタルカーリング(※)にボードゲームの検索手法を取り入れたAI「じりつくん」を開発しました(動画2)。じりつくんでは、Expectimaxによるゲーム木探索を行う手法を取り入れています(解説3)。狙い通りの場所にストーンが投げられなかった場合の可能性を確率分布によって吸収し、そこから先の試合展開と最終的な得点の期待値を計算して「どのぐらいの得点が得られるか」を計算します。
さらに、Expectimaxによるゲーム木探索によって得られたストーン座標値をニューラルネットワークに入れて機械学習させ、最終的に自分のチームが何点取る確率が高いかを計算させました(図2)。
実際のゲームでは、起こりうる局面が何通りもある上、プレイヤーの技量やアイスコンディションの影響で自分たちの望む座標にストーンを置けないという状況が発生します。私たちが開発したツールは、「このあたりを狙えば、多少のズレがあったとしても、最終的に得点が得られ、勝てる確率が高い」という予測をもたらすものです。プレイヤーだけでなくテレビ中継での解説などにも活用できると考えられ、実用化を目指して研究を続けているところです。
※電気通信⼤学の伊藤毅志研究室が中⼼となって開発したカーリング戦略⽀援ツール
解説
解説1:運動の相互知覚を通したコミュニケーションの進化
運動のみからコミュニケーションを行うために、他の個体までの距離がわかるセンサと車輪のみから構成されるロボットを用意。ロボットはリカレントニューラルネットワークによって制御されセンサから感知した他のロボットの動きに基づいて行動を行う。3体のロボットは「お互いに離れずに一定距離以上進む」というタスクが課され、それを達成できるように遺伝的アルゴリズムによって進化する。3体がまとまって進む方向は決まっておらず、ロボット同士がコミュニケーションを行って進行方向を決定する。
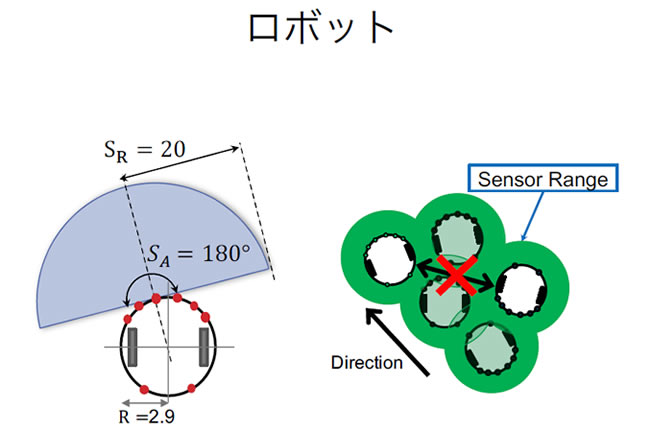
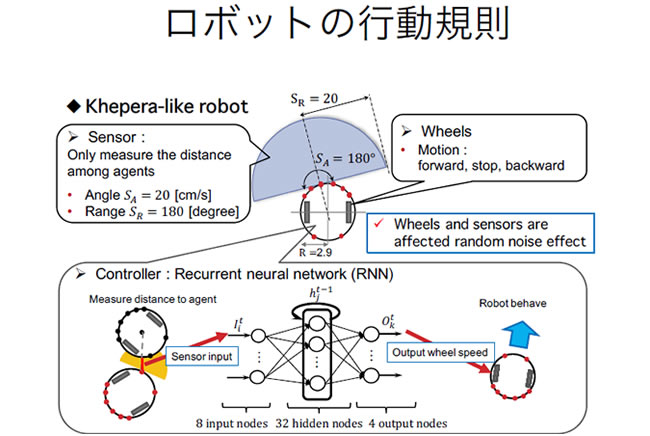
運動の相互知覚を通したコミュニケーションの進化slideshow(動画を再生)
解説2:ディープラーニングによるロボットの自己位置推定
ロボットの一人称視点画像とそのときの自己位置との関係を学習する畳み込みニューラルネットワーク(CNN)を用いて自己位置推定を行う。世界がブロック単位で構成されているゲーム空間であるMinecraft(https://minecraft.net、 https://planetminecraft.com/project/monumental-imperial-city)上で実験を行い、未知のデータに対する精度、ノイズに対する頑健性の検証を行った。
ロボットが動きながら得られる複数の画像情報を自己位置推定に利用するために、CNNに再帰的な構造を追加したリカレント型畳み込みニューラルネットワーク(RCNN)を自己位置推定に用いて、そのときの性能を検証。実験の結果、RCNNはCNNによる一枚の画像からの推定よりも、また、CNNによる複数の推定結果の平均よりも、高い精度で推定可能であることを示した。


解説3:Expectimaxによるゲーム木探索
通常のMinimax法に対しチャンスノードと呼ばれる確率的な分岐点を導入し、不確定ゲームにおいてMinimax探索を行う手法。デジタルカーリングへの適用にあたっては、①候補手である投球情報には実数値が含まれるため無数に存在する、②デジタルカーリングではAIの出力した手(投球情報)に乱数が加わるため、生じうる局面が不確定であるという2つの課題があり、これに対しては、①盤面全体に格子状に細かく離散化した座標を設定し、その座標を投球の目標座標として有限個の候補手を生成する、②生じうる局面を「狙った座標から一定半径内の座標にズレた場合に生じる局面」に限定し、候補手の評価を生じうる複数の局面のから求められる評価値の期待値により候補手の評価を行うことで課題を解決している。
これまで、デジタルカーリングにおける公式大会は二回行われており、一回目は準優勝、二回目は優勝している。
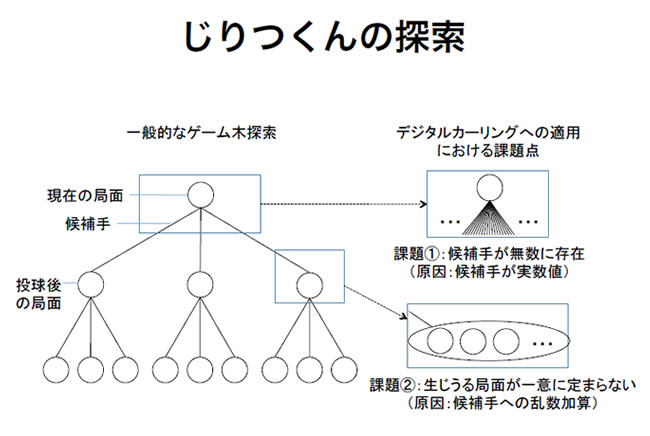
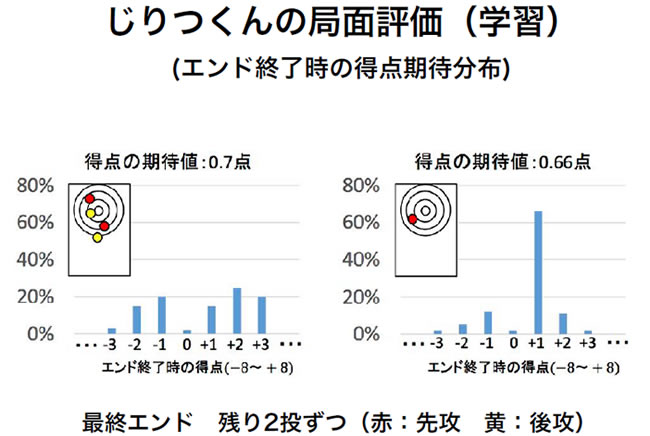
Expectimaxによるゲーム木探索slideshow(動画を再生)