
日本学術振興会育志賞受賞研究 「深層学習を加速する汎用計算アーキテクチャに関する研究」の紹介

情報科学研究科 情報エレクトロニクス専攻
博士後期課程2年 植吉 晃大
はじめに

この度、平成30年度日本学術振興会育志賞を受賞する機会を賜りました。本賞は、我が国の学術研究の発展に寄与することが期待される優秀な大学院博士課程学生を顕彰することで、その勉学及び研究意欲を高め、若手研究者の養成を図ることを目的とし、天皇陛下から御下賜金を賜り、創設された賞です。本受賞は、「深層学習を加速する汎用計算アーキテクチャに関する研究」が評価されました。ここでは、その研究内容について紹介させていただきます。
深層学習(ディープラーニング)により、画像・音声認識、自然言語処理等が飛躍的に進化を遂げました。そんな需要が高まる中、どのような計算機構を世の中で実用していくかが鍵となっています。現在のディープラーニング技術は、サーバ・クラウド上の高性能な計算機で学習されたデータ(特徴量)を用いて、スマートフォンやセンサのような小さな組み込みデバイス上で認識・制御を実行します(図2)。この組み込みデバイス側では、実世界での物理的な制約が厳しい状況で計算をしなくてはなりません。私の研究では、この小さな端末上で効率よく認識・制御を実行できるような新しいハードウェアシステムの構築を目指しました。
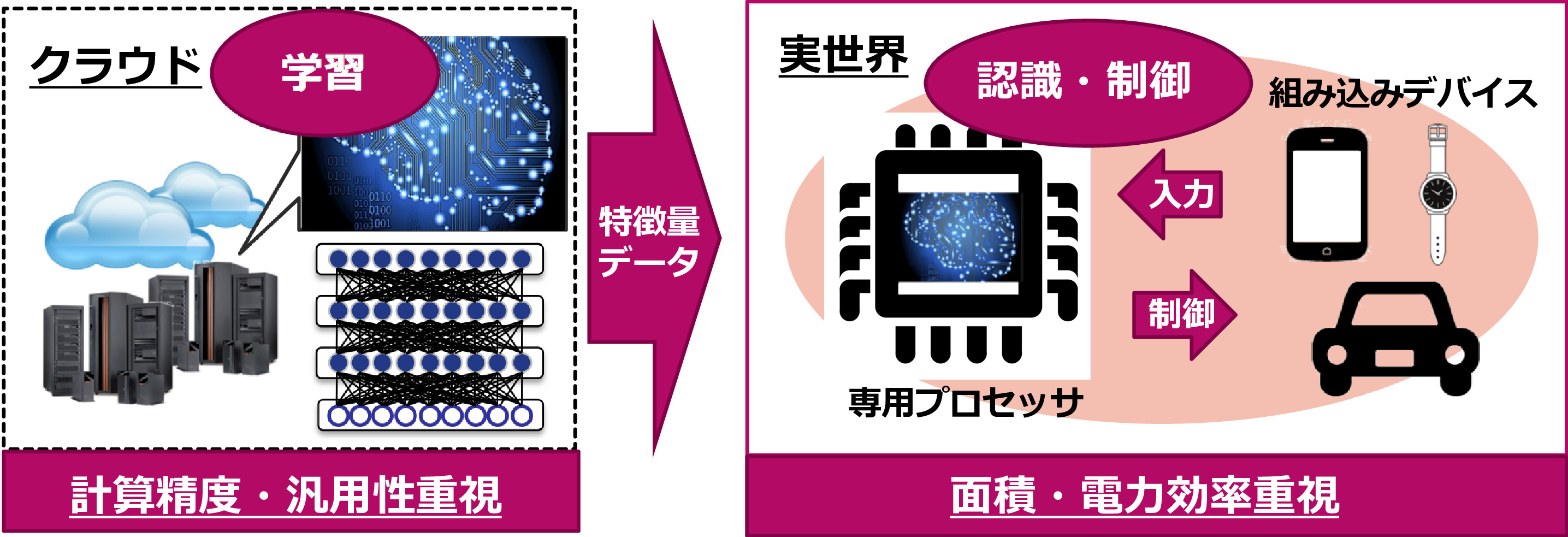
図2:ディープラーニング専用ハードウェアの活用図
ディープラーニングでは、ニューラルネットワーク(以下NN)と呼ばれる、脳機能を模したアルゴリズムが用いられます。しかし、NNは計算量が膨大なため、限られた制約下では、計算が困難となります。実用的に応用・発展を遂げていくためには、時間効率と電力効率の双方を最適化したハードウェアシステムが求められます。この実現のために私は、実際に情報処理を行う半導体集積回路(LSI)自体の効率化と、アルゴリズムの効率化の両面を考慮して、新しいシステムを創出してきました。以下では、私が行ってきた、極低電圧環境下でのエラー耐性評価と、計算処理の軽量化を応用した高効率回路のそれぞれについての研究を紹介します。
極低電圧環境下でのエラー耐性評価
NNの計算は、その特性上、一つ一つの計算に対する精度は高く求められることがありません。そこで、ある程度計算精度が許容されるという条件をアルゴリズム側に与えると、新しいアプローチをLSI上で適用させることができます。私が行った研究では、まず、確率的に動作する、制約つきボルツマンマシン(Restricted Boltzmann Machine: RBM)のディジタル計算機構を提案し、そこで用いる内部メモリに意図的にエラーを注入し、その耐性を評価しました(図3)。このノイズは、低電圧電源下で動作した際のゆらぎを模しており、RBMの耐ノイズ性の強さから、簡単な画像認識であれば、消費電力を大きく削減できることを示しました [1]。

軽量計算処理を応用した高効率回路
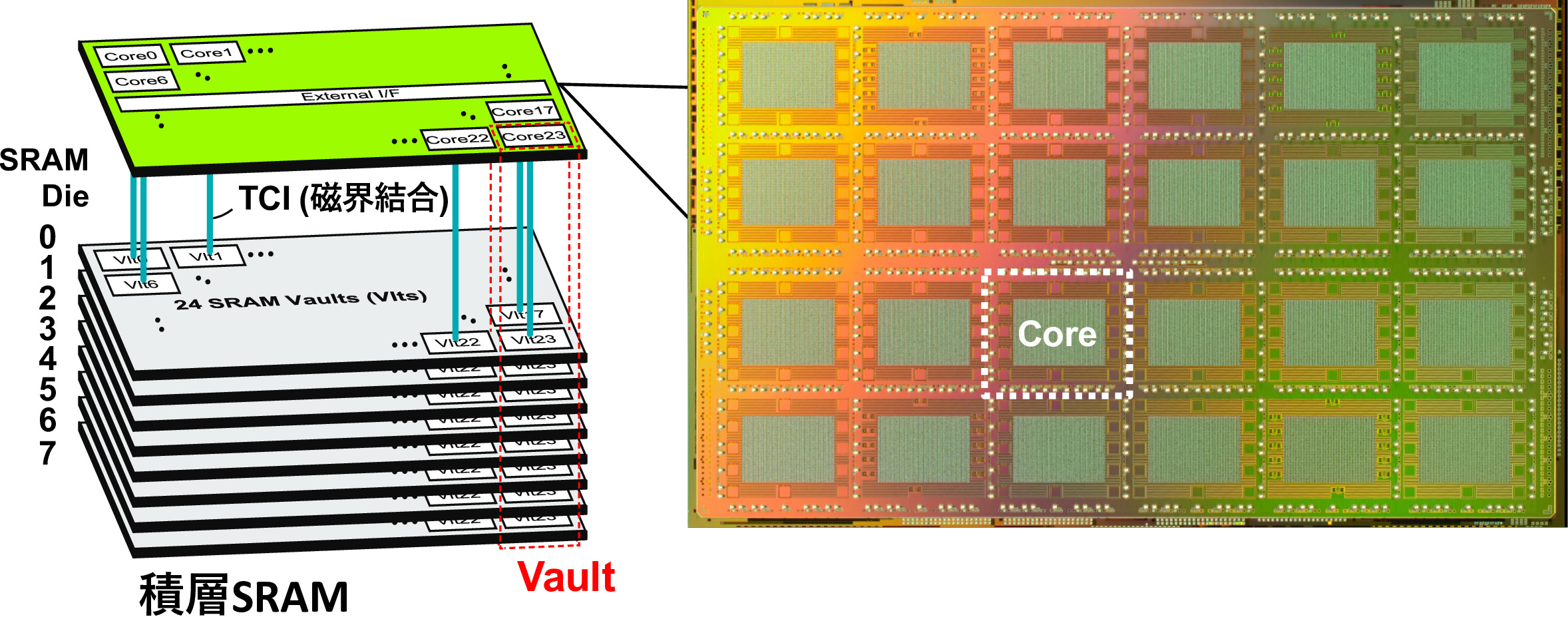
ここでは、ディジタル計算に適した表現方法によるNN計算手法と、その応用回路について解説します。NNの計算では、多数の乗算を繰り返す必要があるのですが、ディジタル回路上において、乗算回路は四則演算の中でも非常に大きな面積と電力を要します。この乗算器を利用せずに、近似的に計算する方法として、対数量子化が知られています。これは、2を底とする対数表現のみを使って近似することで、乗算相当の計算を加算のみで実現します。加算のみを利用した計算機では、一つ一つの値を、計算の最小単位である1ビットずつ計算できるので、計算精度を可変にし、かつ密で小さな回路を可能とします。これらを組み合わせることで、NNの有する情報量を損なうことなく、計算コストを最小限に抑えることができます。今回の研究ではこの回路をLSI上に実装し、慶應義塾大学との共同研究による、3次元メモリシステムと統合させ、高速かつ低電力なハードウェアシステムを実現しました[2,3]。
おわりに
これらの研究成果は、多数の論文誌や国際会議で発表してきました。中でも、半導体業界最高峰の国際会議であるInternational Solid State Circuit Conference (ISSCC)での発表も行い、東アジアの学生発表の中で選ばれる、Silkroad Awardを受賞しています。
現在、本分野の研究は、凄まじいスピードで論文が量産されています。こうした中で、本学でも名乗りを挙げて世界と戦うのは、とてつもない労力が必要です。しかし、一度認められれば、世界が大きく広がることを身を持って感じました。移り変わりの激しい分野ではありますが、最先端の技術動向に適応する能力を鍛え、自分の信念と特色を活かした研究活動で、今後もこの業界に貢献していきたいと考えております。また、上記以外にも、以下のプロジェクトでも研究成果を公開していく予定ですので、興味を持たれた方はぜひお訪ねください。
JST ACT-Iプロジェクト「情報と未来」のページ
http://www.jst.go.jp/kisoken/act-i/project/111C001/111C001_2018.html
北海道大学・情報科学研究科・集積アーキテクチャ研究室(所属研究室)のホームページ
http://lalsie.ist.hokudai.ac.jp/jp/
[1] T. Marukame, K. Ueyoshi, T. Asai, M. Motomura, A. Schmid, M. Suzuki, Y. Higashi, and Y. Mitani, "Error tolerance analysis of deep learning hardware using restricted Boltzmann machine towards low-power memory implementation," IEEE Transactions on Circuits and Systems II, vol. 64, no. 4, pp. 462-466, 2017.
[2] K. Ueyoshi, K. Ando, K. Hirose, S. Takamaeda-Yamazaki, M. Hamada, T. Kuroda, and M. Motomura, "QUEST: Multi-Purpose Log-Quantized DNN Inference Engine Stacked on 96-MB 3-D SRAM Using Inductive-Coupling Technology in 40-nm CMOS," IEEE Journal of Solid-State Circuits, vol. 54, no. 1, pp. 186-196, 2019.
[3] K. Ueyoshi, K. Ando, K. Hirose, S. Takamaeda-Yamazaki, J. Kadomoto, T. Miyata, M. Hamada, T. Kuroda, and M. Motomura, "QUEST: A 7.49-TOPS Multi-Purpose Log-Quantized DNN Inference Engine Stacked on 96MB 3D SRAM using Inductive-Coupling Technology in 40nm CMOS," 2018 International Solid-State Circuits Conference (ISSCC 2018), San Francisco Marriott Marquis, San Francisco, US, Feb. 11-15, 2018.